Convolutional Neural Networks I: Intuition from CV
Created by Richard Jiang on 15th, Dec, 2017.
This blog was drafted 2 weeks earlier, yet it didn’t come up until recently; I guess it’s because of the end-of-year-and-happy-2017 series of events lol. Nevertheless, let’s get started.
So the first semester in which I was TA for a module offcially ended. It is true that time arrangement has been way more flexible compared to undergrad studies, and has hence given some benefits, for example, my friend and I got the chance to sit-in for more advanced, yet quite related course: the CS5242: Neural Networks and Deep Learning (for free, of course).
The course reminds me of the famous Stanford CS231n: Convolutional Neural Networks for Visual Recognition. And it turns out that we have to refer to the materials from CS231n quite a lot of times along the way just in order to understand sth. It was a bit troublesome at the beginning of our sit-in course, though, as sometimes the explanation from the lecturer is not clear enough. It is during this look-up time that I realize that I just cannot find a simple, clear, and intuitive guide on CNN on the Internet; yeah there are plenty of them, probably more than sufficient, but from my own perspective, they are either too wordy or too sophisticated (or too “cool”, because of all the formulas). Therefore, I have decided to write on this set of tutorials.
It all came together when I saw the process of ‘convolution’: a sliding window with numbers inside, appearing on the screen; it instantly took me back to the time of CS4243: Computer Vision and Pattern Recognition by Prof. Ng (seriously, to me one of the most interesting modules in CS department together with CS3217, and it kinda gave me the incentive to pursue a higher degree in related fields).
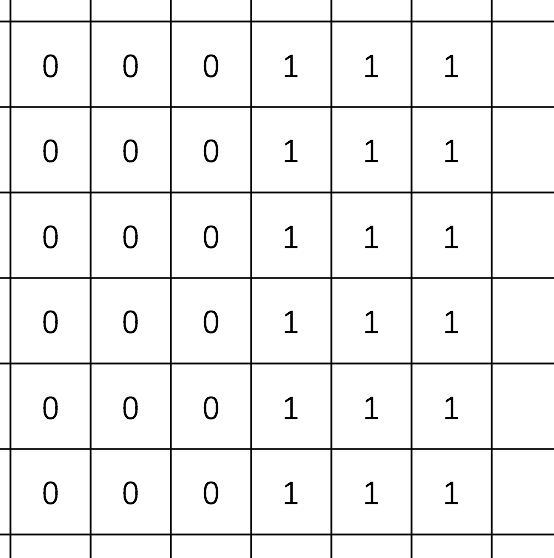
To begin with this set of tutorials, I’d like to discuss about one of the fundamental concepts in CV: edge detection. Consider the image below: the black and grey areas are separated by the line in between.

Now let’s use 1 and 0 to represent the pixel density (or color, if this makes more sense to you) from an image for simplicity. The idea is that we want to use numbers to replace the raw colors such that later we can see the picture from the computer’s point of view. It is pretty clear that the columns of 1’s and 0’s have formed a line of ‘separation’; in other words, a vertical edge.
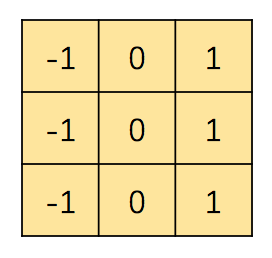
With the numbers inside, now let’s see the matrix listed below. You may treat it as a filter:
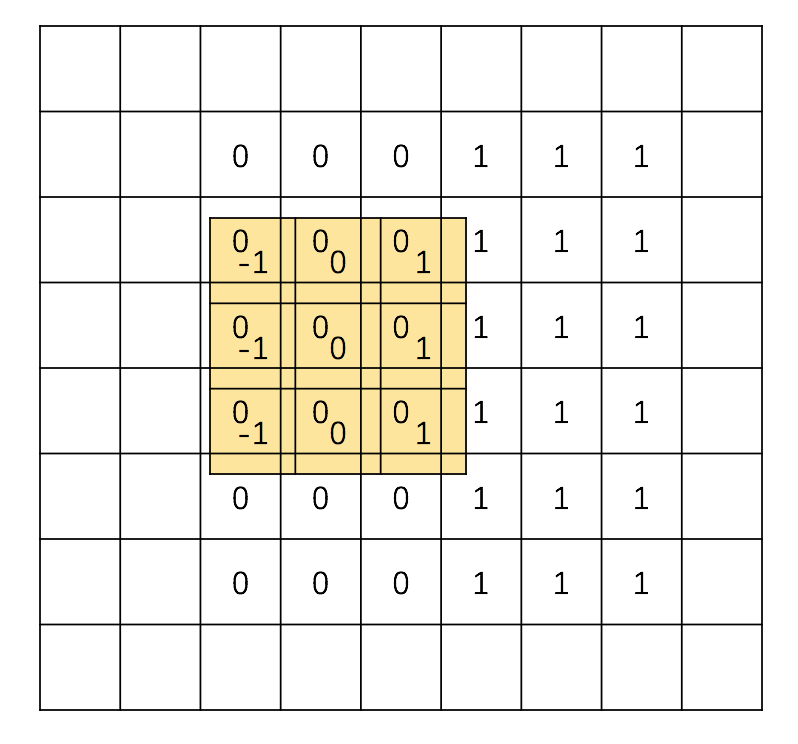
Now the trick: let’s slide the filter through the matrix of the image, for any pixel of the image, let’s replace its original value with the following: do an element-wise product of the filter with the current 3x3 matrix it’s covering inside the image, and then sum all the products up, like this:
After replacement, the original image will become like this:
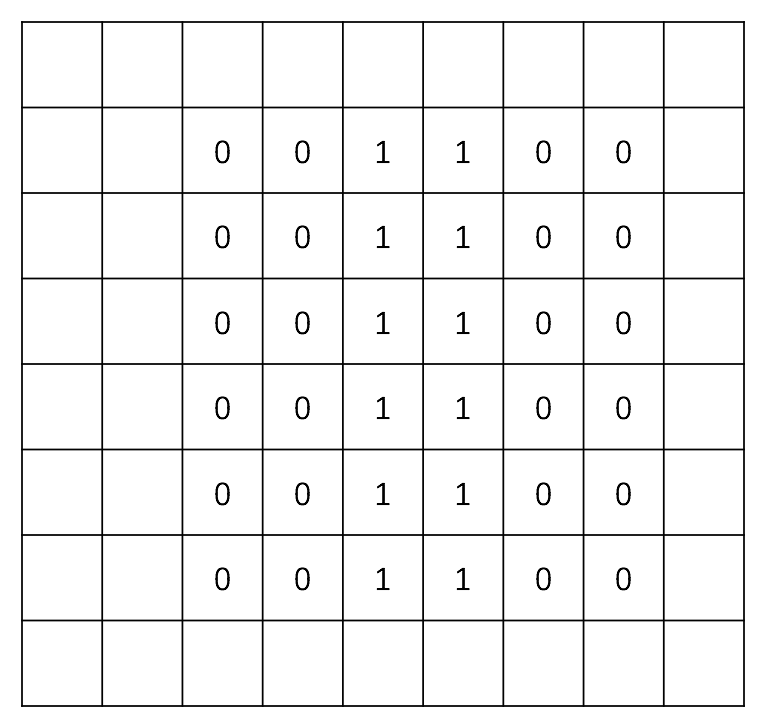
Refer back to our definition for the values, you can see that now the new image has only information regarding the central edge, and all the rest (where the color remains constant) is weakened to 0. If you convert the numbers back to the real pixel RGB color, it’s not hard to guess that the new image will have a shining vertical white line in the middle, with the rest set to black color.
So this is the trick we can do with a simple 3x3 matrix; in fact, the filter we’ve just used is officially the Prewitt Edge Detector. Notice that you may also put the filter in its transpose so it can detect the horizontal edge.
Okay that’s the CS usage of filters, but how about this ‘convolution’ concept?
The idea of convolution, to me, starts from my EE course with signal processing and all that Fourier Transform stuff. The official definition of convolution, as can be found on Wikipedia, is:
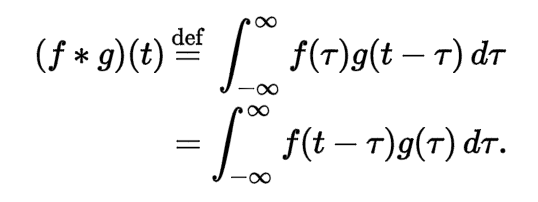
When performing the Fourier transform, the domain is switched from one to the other, and can be regarded as the element-wise product-and-sum. Well, it sounds like what we did just now with the images, right?
Now back to the images: if you think about it in a higher level, just now in the raw image, the edge we detected is actually a feature of it. If we have many of such filters, it is totally possible for us to recognize/detect/extract the important features out of it, for instance, a U-shape curve or sth. Sometimes when you are recognizing sth, you are simply identifying whether there are such features inside the images, aren’t you?
So is the neural network.
And with these concepts and intuitions from CV, we have seen that there are sth useful we can extarct from the numerical representation of images, and these things can be used to represent/stand for the raw images. The process of ‘convolution’ is hence introduced, and we have seen how it can be beneficial to simplify the images. With all the simple features, a neural network can then be studied on how to utilize them better. So I’ll end the introduction here, and in the next few posts, I’ll show a more detailed explanation on Convolutional Neural Networks.